Inside & Outside My Website Traffic
Asssalamualaikum sudah cukup lama rasanya tidak menulis, di sela-sela kesibukan remaja yang cukup menyita waktu, pada tulisann kali ini saya akan membagikan hasil analisa sederhana tentang bagaimana Nginx access log dan Google Analytic mengumpulkan data-data pengujung pada website yang sedang saya kembangkan ini, pertama hasil dari Nginx memliki beberapa file pecahan access log seperti pada tangkapan layar di bawah ini
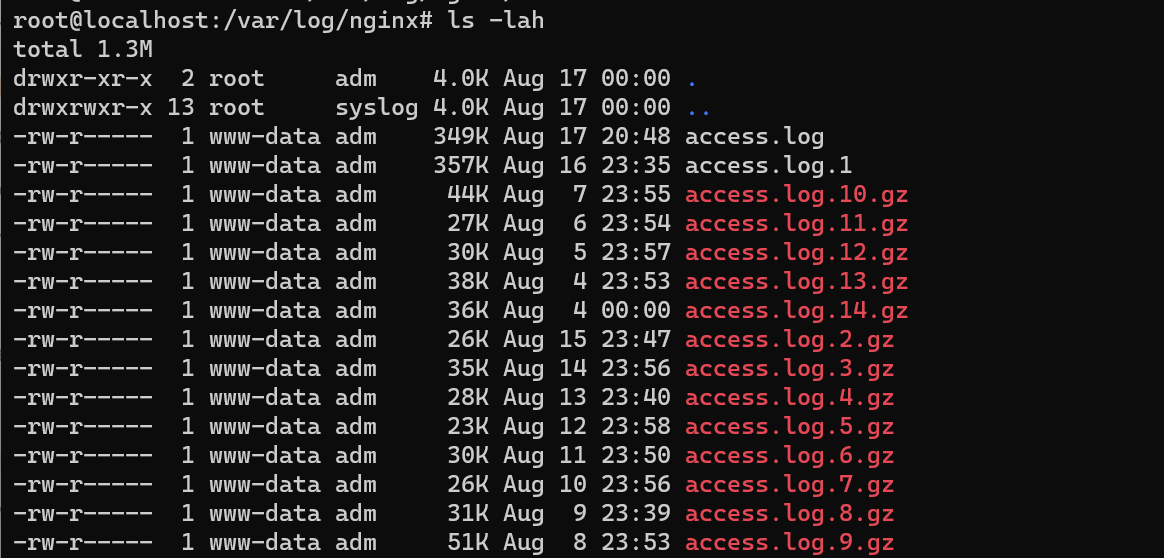
Cara terbaik untuk melakukan analisa Nginx Access Log tersebut tetaplah dengan cara menggabungkannya menjadi 1 access.log tunggal, cara sederhananya dapat menggunakan bash dengan files redirection
cat access.log access.log.1 access.log.2 .... access.log.14 > access.log.finalHasil dari [access.log.final](http://access.log.final) setelah penggabungan beberapa file menjadi seperti di bawah ini detailnya
-rwxrwxrwx 1 user user 8.2M Jul 18 09:51 access.log.final
----------------------------------------------------------
34976 access.log.final
Hasil dari penggabungan dari beberapa file tersebut menghasilkan file sebesar 8.2Mb dan jumlah line of data mencapai 34976 atau 35 ribu line kurang 25 data saja, lalu setelah sudah tergabung menjadi 1 bagaimana cara terbaik untuk menganalisanya? bagi saya cara terbaiknya adalah melakukan parsing 1 per 1 tiap-tiap datannya dan melakukan query insert pada database mysql, mungkin terdengan overkill, namun untuk alasan kecepatan cara ini bagi saya masih yang terbaik, untuk stuktur tabel pada awal proses parsing adalah sebagai berikut ini
| Kolom | Tipe Data |
|---|---|
| id | int (11) |
| remote_addr | text,nullable |
| time | text,nullable |
| request | text,nullable |
| status | text,nullable |
| bytes_sent | text,nullable |
| referer | text,nullable |
| user_agent | text,nullable |
| method | text,nullable |
| uri | text,nullable |
| http_version | text,nullable |
Saya tau mungkin dalam benak pembaca sudah mulai bertanya “kenapa kok tipe datanya ‘text’ dan ‘nullable’” jawaban pastinya “karena saya tidak tau dan tidak ingin begitu memikirkan size datanya”, proses untuk pemindahan data dari file ke database menggunakan python dengan modul mysql.connector sebagai konektivitas client ke database mysql yang ada di server, sederhananya cara cepat untuk melakukan parsing adalah menggunakan regex, berikut ini adalah regex rule yang saya gunakan
log_format = r'(?P<remote_addr>\d+\.\d+\.\d+\.\d+)\s+\S+\s+\S+\s+\[(?P<time>[^\]]+)\]\s+"(?P<request>[^"]+)"\s+(?P<status>\d+)\s+(?P<bytes_sent>\d+)\s+"(?P<referer>[^"]+)+"\s+"(?P<user_agent>(?!http)[^"]*)"'(?P<remote_addr>\d+\.\d+\.\d+\.\d+)\s+\S+\s+\S+\s+\[(?P<time>[^\]]+)\]\s+"(?P<request>[^"]+)"\s+(?P<status>\d+)\s+(?P<bytes_sent>\d+)\s+"(?P<referer>[^"]+)+"\s+"(?P<user_agent>(?!http)[^"]*)"Hasil dari re.match akan langsung menghasilkan list pyton sesuai dengan hasil regex yang telah didefinisikan, hasil data yang berhasil masuk ke database dari data raw berjumlah 34976 menjadi 34159 data saja yang berhasil masuk, jadi ada 817 data yang tidak berhasil di-parsing atau sekitar 2.34 % yang gagal dari hasil regex di atas. Sebenarnya data yang berada pada database harusnya sudah dapat diolah dengan cepat, namun saya harus mengkonversi beberapa data “mentah” dari log agar dapat lebih mudah dilakukan analisa, berikut ini adalah contoh data mentah dari “access.log.final”
192.241.212.35 - - [17/Jul/2023:00:00:39 +0800] "GET / HTTP/1.1" 403 134 "-" "Mozilla/5.0 zgrab/0.x"
103.94.234.29 - - [17/Jul/2023:00:01:12 +0800] "\x16\x03\x01\x01\x07\x01\x00\x01\x03\x03\x03\x8D\x00\xAC\xB0K\x97}\xD7\xA6\xFC\xE8\xD5k|\xDB\x91R\xF3\x06\xDCX\xABs\x8C&]\x95<'\xC4\x12\xAE \x958\xC1\xDA\x7FI\x8D\x22\x930B\xD4\x04%\x05O\x09\xB4\xF0\x8Db4nD=\xAB\xB0h\xC4\xF6\xC3j\x00&\xC0+\xC0/\xC0,\xC00\xCC\xA9\xCC\xA8\xC0\x09\xC0\x13\xC0" 400 166 "-" "-"
121.62.19.203 - - [17/Jul/2023:00:28:34 +0800] "GET / HTTP/1.1" 400 666 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36"
121.62.19.203 - - [17/Jul/2023:00:28:49 +0800] "GET / HTTP/1.1" 400 666 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"Data yang perlu dilakukan konversi ulang adalah 17/Jul/2023:00:00:39 +0800 , data tersebut adalah timestamp dari log format nginx, saya harus merubahnya menjadi datetimes sql agar dapat dilakukan query sorting yang lebih optimal, sebenarnya proses ini dapat dilakukan pada saat proses parsing, namun karena keteledoran saya jadinya benar-benar data raw yang masuk ke database, lalu bagaimana caranya merubah data tersebut menjadi data datetimes, cara tercepatnya adalah menggunakan query di bawah ini
UPDATE nginx
SET datetimes = STR_TO_DATE(SUBSTRING_INDEX(timestamp, ' ', 1), '%d/%b/%Y:%H:%i:%s');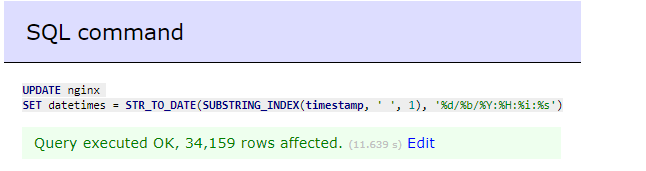
Proses eksekusi query di atas memakan waktu sekitar 11 detik untuk 34 ribu data, sejauh ini mungkin ini adalah cara terbaik yang saya punya untuk melakukan konversi daripada mengulang dari awal proses parsing-nya, setelah semua sudah siap untuk di query berikut inilah hasil analisa yang dapat saya bagikan kepada para pembaca.
IP Address Traffic Story
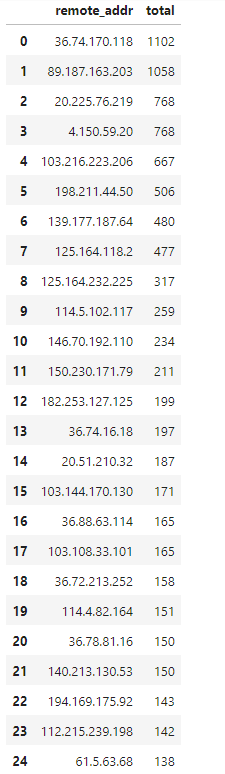
Hasil dari grouping database menunjukan 2 IP tertinggi tembus angka 1000 akses, saya mencoba melakukan visualisasi dengan barplot dan berikutlah hasilnya, tujuannya agar lebih enak saja tampilan visualnya
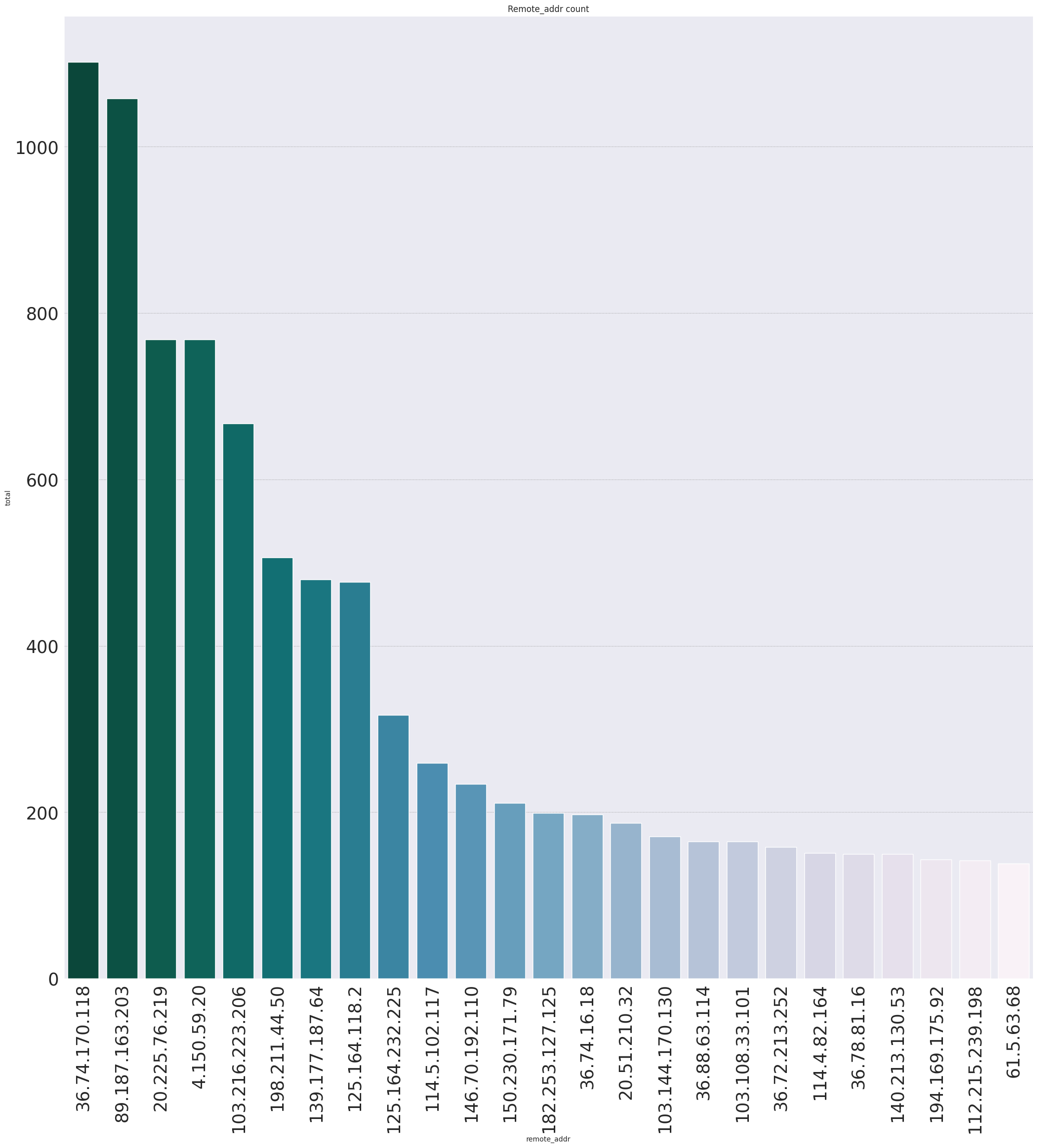
Beberapa IP dengan jumlah pengakses tertinggi adalah 36.74.170.118 , 89.187.163.203 dan lainnya **jika dikelompokan berdasarkan negaranya maka datanya bisa dilihat pada tabel di bawah ini
| IP | Lokasi |
|---|---|
| 36.74.170.118 | Indonesia, Surabaya |
| 89.187.163.203 | Singapore, Singapore |
| 20.225.76.219 | United States, Texas |
| 4.150.59.20 | United States, Texas |
| 103.216.223.206 | Singapore, Singapore |
Pengakses tertinggi tetap dari negara saya sendiri yaitu Indonesia, dilihat dari format IP Indonesia, sepertinya beberapa pengakses website saya adalah hasil dari Masking IP dari ISP Indiehome, lalu sisanya adalah pengakses dari luar negeri seperti Singapore dan USA, menarik. Tapi, kenapa bisa website saya diakses dari Singapore dan USA, mari kita lihat isi request miik mereka dimulai dari negara Singapore: **
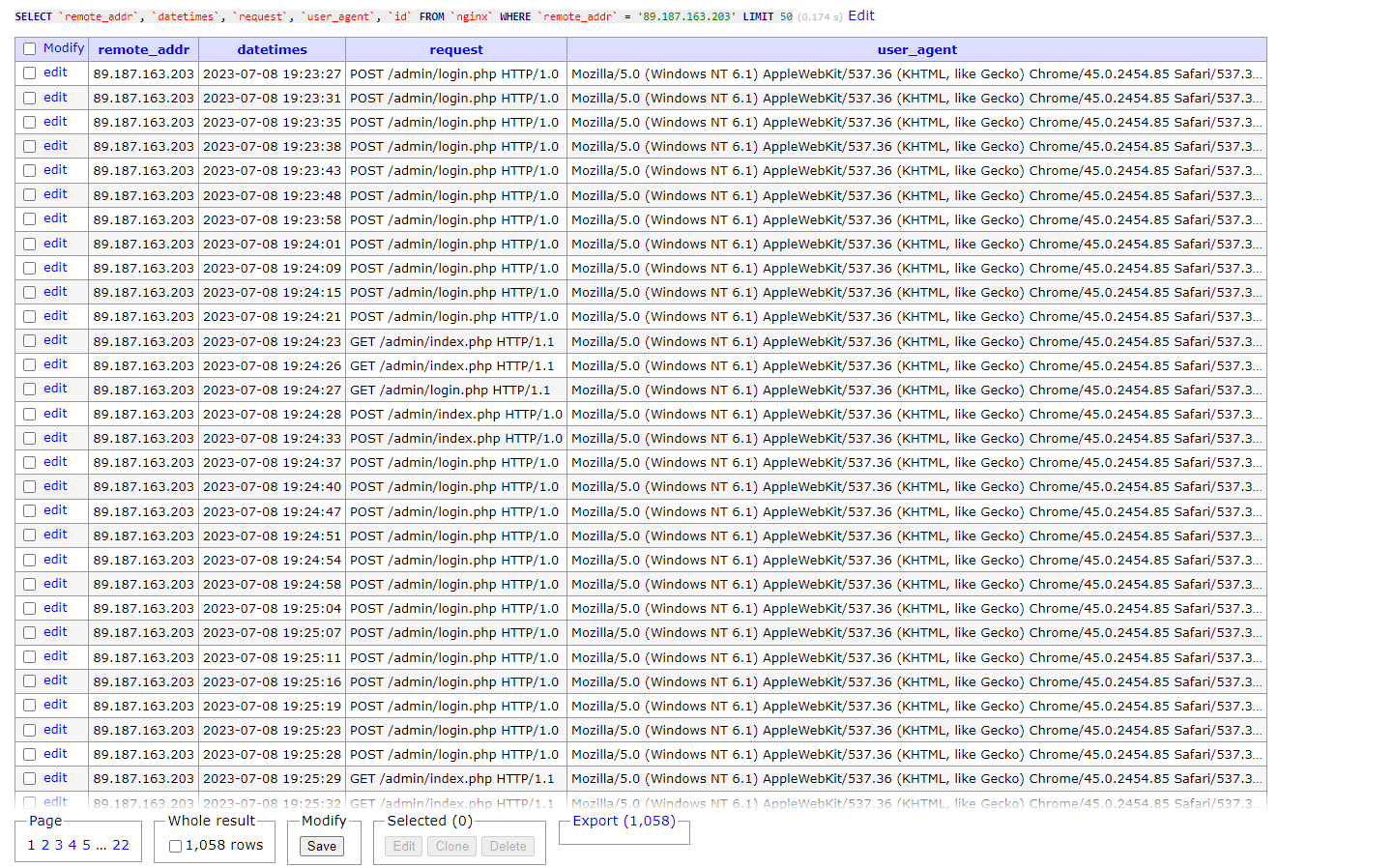
89.187.163.203
103.216.223.206
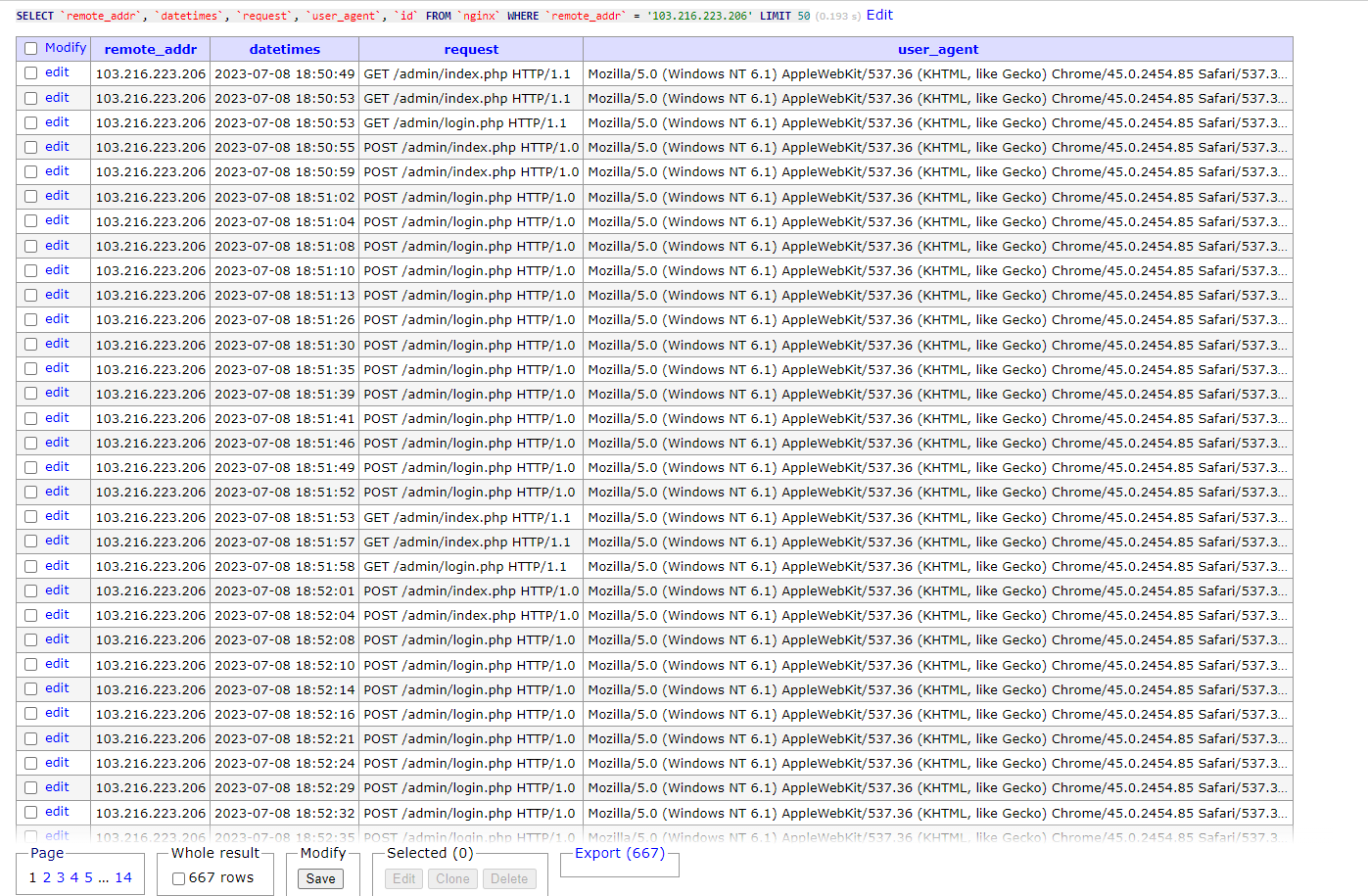
(**103.216.223.206)** Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 OPR/32.0.1948.45
(**89.187.163.203)** Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 OPR/32.0.1948.45Dan benar saja, isi dari log dari IP tersebut melakukan request POST dan GET ke URL (/admin/index.php | /admin/login.php) terlihat dari stukturnya kuat dugaan saya IP tersebut melakukan Bruteforce ke endpoint tersebut, saya sebagai pemilik website hanya dapat berargumentasi sebagai berikut ini
- Jika memang endpoint tersebut adalah endpoint yang saya gunakan untuk urusan Administratif website, apakah saya seceroboh itu menggunakan username & password yang ada di dalam isi dari rockyou.txt ? tentu tidak dong, eh.
- Jika endpoint tersebut bukanlah tempat yang saya gunakan untuk urusan Administratis website, lalu kenapa endpoint tersebut tersedia? apakah saya ceroboh tidak menghapus endpoint tersebut? atau memang sengaja tinggalkan, eh🍯
Kesimpulan yang saya dapat ambil dari kedua IP yang berasal dari Singapore tersebut aksesnya bersifat mengancam dan dengan sengaja melakukan hal tersebut, huh! Lalu IP dari Amerika apa saja yang dilakukan?
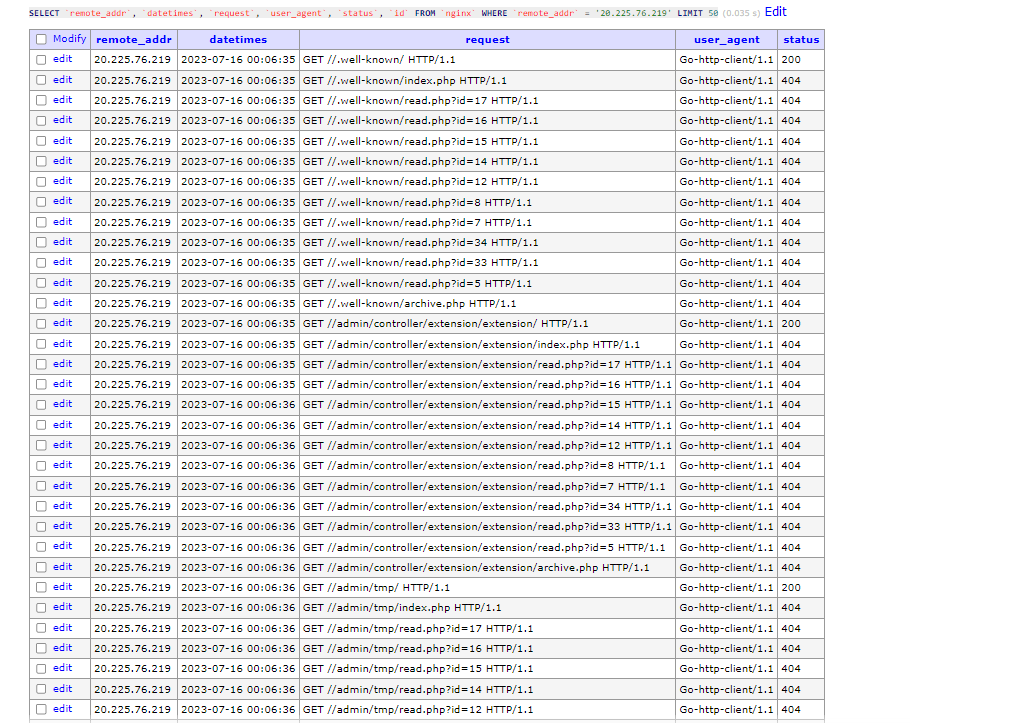
20.225.76.219
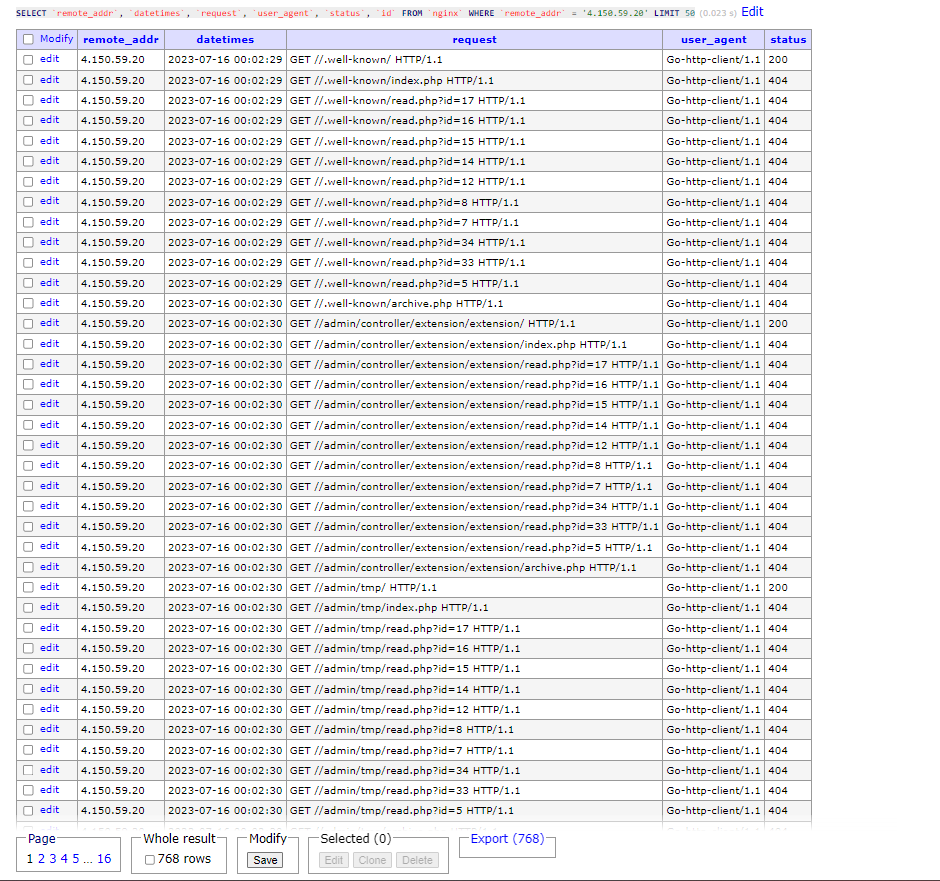
4.150.59.20
(**20.225.76.219)** Go-http-client/1.1
(**4.150.59.20)** Go-http-client/1.1Terlihat pada kedua tangkapan layar di atas, kedua IP dari USA tersebut melakukan semacam crawling atau directory scanner yang menghasilkan 404 dari setiap request-nya lalu User Agent dari kedua IP tersebut kuat dugaan saya menggunakan bahasa pemrogramman GO untuk melakukan http client request. Dilihat dari pola “serangan”-nya tindakan kedua IP dari USA tersebut tidak begitu “mengancam”, karena setelah dianalisa hampir semuanya mendapatkan response 404. Lalu? bagaimana dengan IP lokal dari Indonesia yang berada pada urutan pertama?
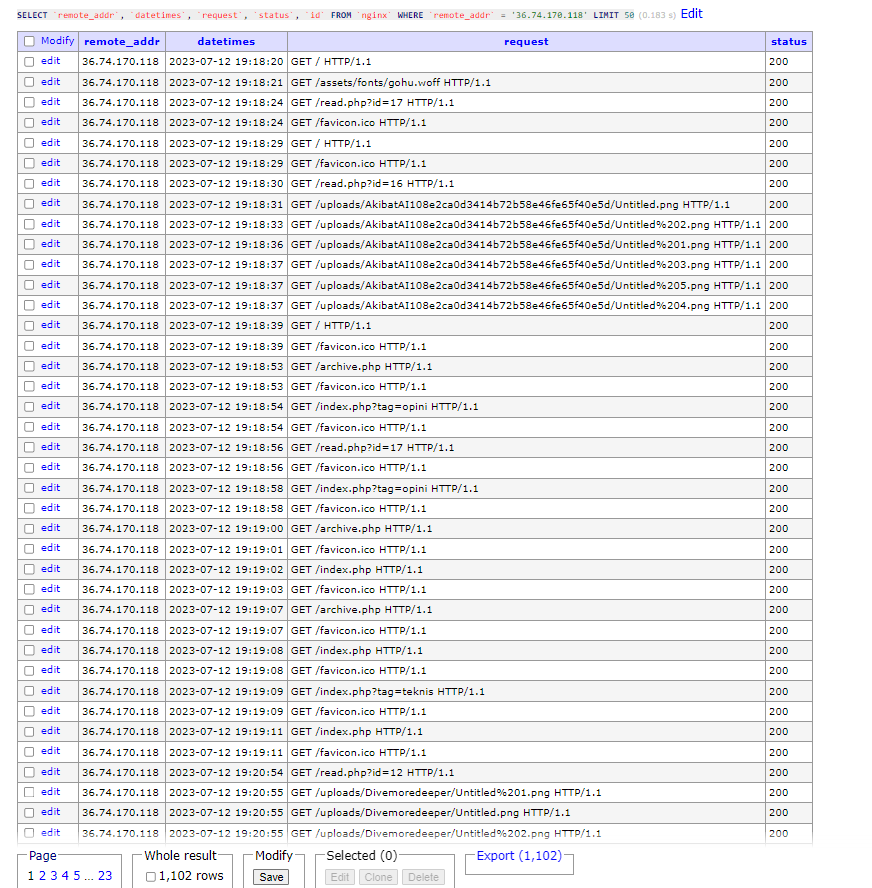
Hasilnya bisa dilihat, pada 50 data awal semua datanya mengembalikan hasil 200 ok dan dilihat dari request-nya terlihat bahwa semua request berbentuk normal dan terlihat seperti pengunjung biasanya, bisa dikatakan bahwa IP tersebut adalah IP lokal yaitu orang asli. Setelah behavior para pengunjung website berbasis request log, menarik juga untuk melihat statistik para pengunjung melalui status code dari respons http server
HTTP Status Code Story
Pertama mari dikelompokkan tiap-tiap status code yang ada di dalam database berdasarkan jumlahnya dan di bawah ini adalah hasil tangkapan layarnya
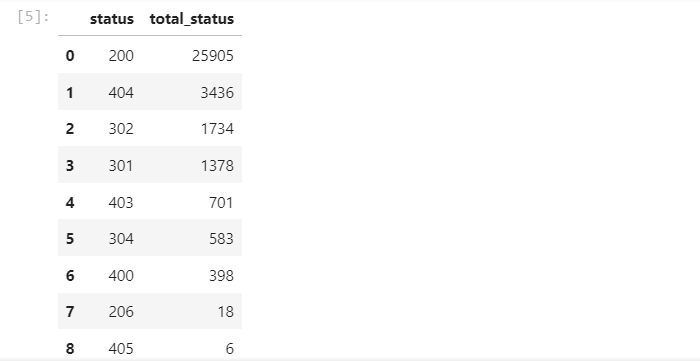
Terlihat seperti status code yang normal, dengan banyak mengembalikan nilai 200 ok sebanyak 26 ribu kurang 10 buah saja. Secara kasar ada sebanyak 24.16 % status code selain 200 ok , dari data ini hal yang dapat dielaborasi lebih lanjut adalah statistik dari tiap-tiap IP dalam mendapatkan hasil dari status code yang ada
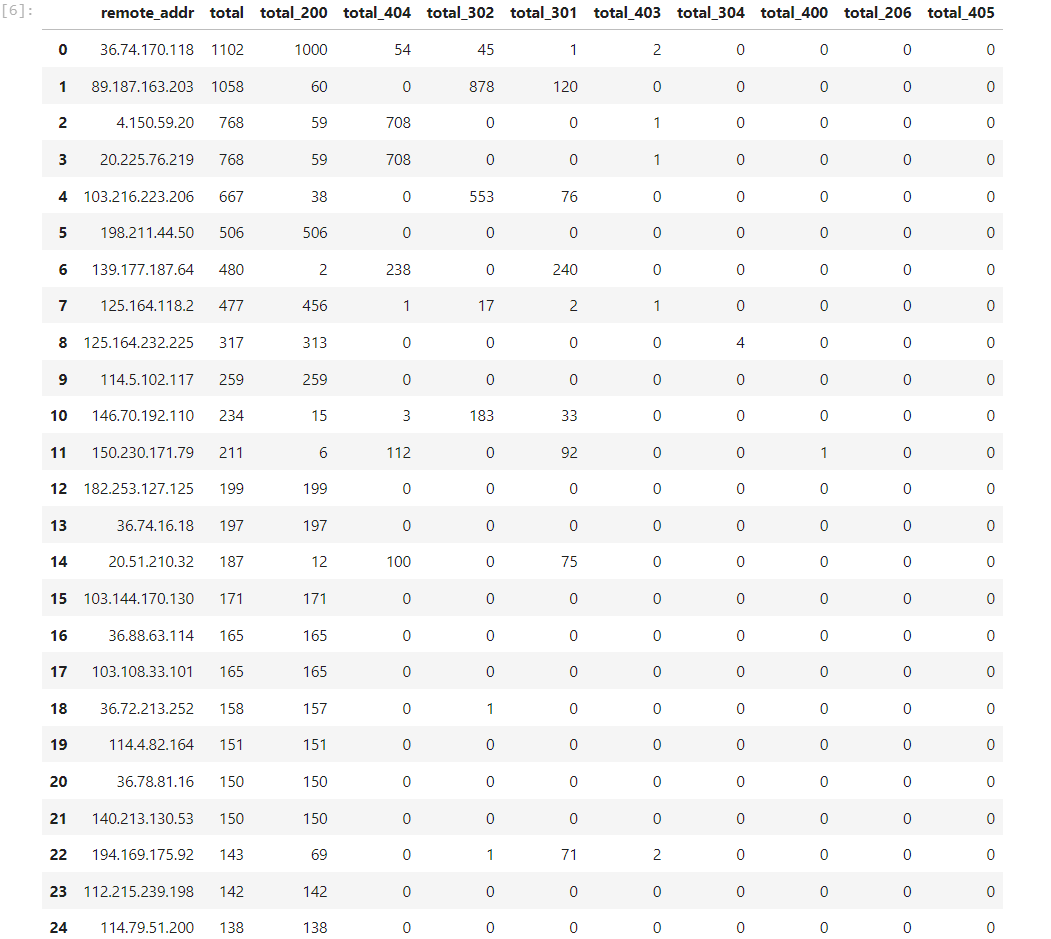
Pada tangkapan layar berupa tabel statistik di atas, sebagai “sysadmin” atau sejenisnya dalam menanggapi data di atas akan sangat-sangat beragam, tapi jika saya yang menjadi “sysadmin” dan mendapati data di atas, langkah terbaik adalah menginvestigasi hasil dari ip yang “bengkak” status code terutama “404”, lalu mencari behaviour-nya si IP sebenarnya sedang melakukan apa, sisanya akan melakukan mitigasi berupa Blocking, selanjutnya setelah melihat statistik status code hal yang dapat dilakukan adalah mempelajari HTTP Method apa yang sering diakses dan apa saja sih yang sedang dilakukan, berikut
HTTP Method Story
Pertama-tama mari kelompokan setiap Http Method untuk mengetahui jumlahnya dari tiap-tiap Method itu sendiri

Dari tangkapan layar di atas, terlihat ada beberapa HTTP Method yang umum seperti GET,POST,HEAD,OPTIONS serta ada beberapa HTTP Method yang “tidak lazim” seperti REQMOD,SSTP_DUPLEX_POST dan beberapa lainnya yang sangat-sangat tidak bisa dikenali, saya berasumsi hal ini dikarenakan karena adanya kegagalan Handshake antara client dengan SSL Server, bagaimana ini bisa terjadi akan dicari tau di kemudian hari 😉 mari sekarang berfokus pada statistik tiap-tiap IP dengan HTTP Method-nya dengan melakukan filtering (membuang) terhadap HTTP Method** yang mengalami kegagalan
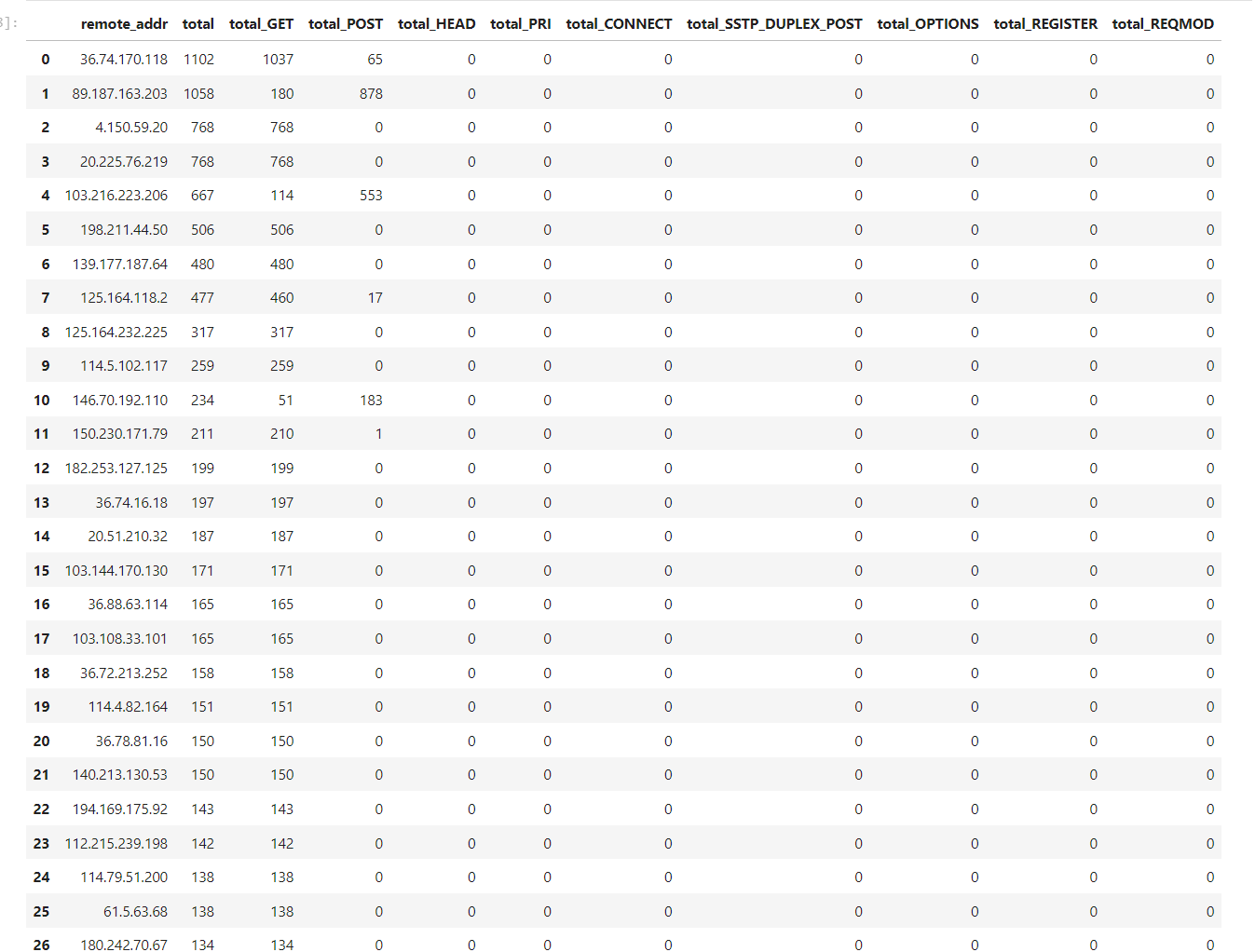
Dari statistik tangkapan layar di atas, kita bisa melihat bagaimana tiap-tiap IP melakukan Request ke Server, dari tipe website yang saya kembangkan yang sifatnya hanya “Blog” dan hanya Read Only, terdapatnya sebuah Method selain “GET” cukup aneh, dan dari sini harusnya kita bisa menginvestigasi lebih dalam seperti pada awal artikel yang saya tulis ini. Setelah ini apa? mari kita melihat di pukul berapa orang-orang mengakses website saya
Clock Telling Story
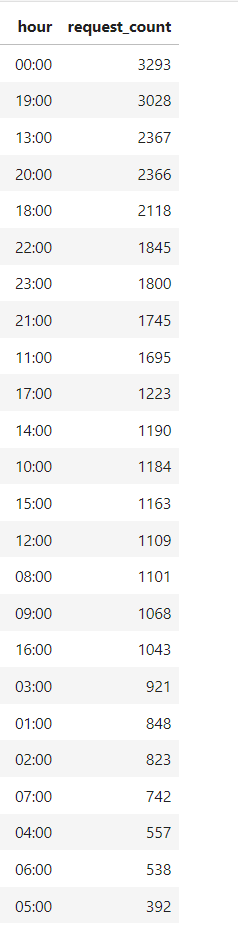
Dari data “waktu” di atas, sebenarnya cukup janggal, tidak! Tapi sangat-sangat janggal terlihat pada statistik waktu di atas orang-orang paling “aktif” mengakses website saya berada pada jam 00:00 yang mana di tengah hari, apakah ini normal? seharusnya tidak, asumsi saya hal ini terjadi karena time log format nginx mengikuti server saya yang “sedang” berada di luar negeri, hal ini akan menjadi pelajaran berharga, karena dari data ini saya tidak dapat menggali apapun agar menjadi informasi yang Relevan, mari berlanjut pada lokasi para pengguna.
My Website Visitor Location
Setiap pengguna yang melakukan akses ke website saya pasti akan membawa IP(Internet Protocol) ADDRESS , IP ini akan membawa biasanya dari ISP provider internet yang sedang dipakai layanannya, bisa sekali 1 IP milik beberapa pengguna karena pada ISP akan menggunakan konsep masking ip untuk menghemat penggunaan IP itu sendiri tentunya. Lalu, apa sih yang kita bisa gali dari sini? benar! kita bisa mengetahui Lokasi “ISP” dari IP dari para pengguna dengan memanfaatkan salah satu tools yang ada di internet yaitu, https://ipinfo.io/$1
Dengan tools tersebut kita dapat mengetahui lokasi dari tiap-tiap IP yang kita lempar pada paramter pertama $1 seperti berikut ini contohnya
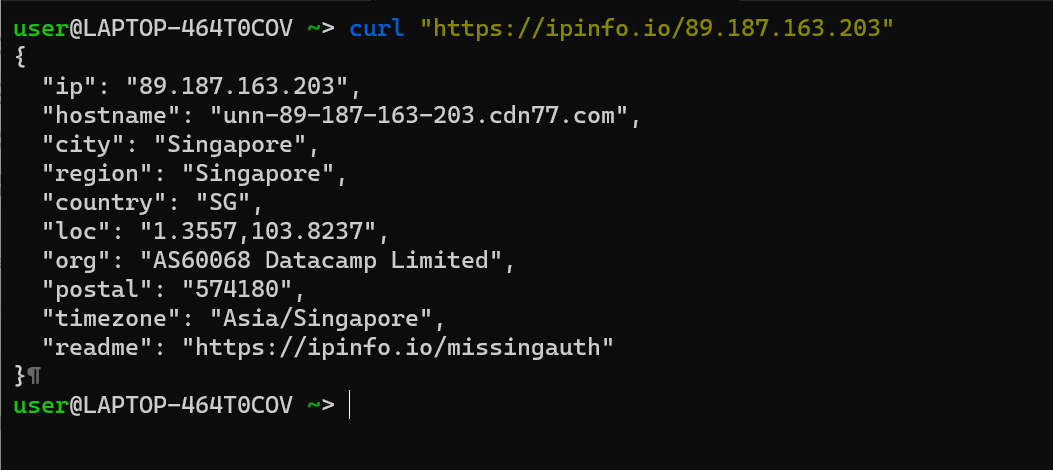
Dari cara di atas kita mendapatkan lokasi berupa City,Region,lat,long, dan Country informasi ini akan sangat bermanfaat untuk dapat memetakan para pengguna website saya, tapi ternyata ada limitasi query sebanyak X yang belum saya ketahui secara pasti untuk dapat menggunakan curl teknik ini, namun yang terjadi adalah pada saya menggunakan curl ini terdapat rate limiting yang menyebabkan saya tidak dapat melakukan query, lalu? apakah tidak ada solusi? tentu ada! Mari kita telaah dulu ide dari pengumpulan data ini, pertama saya menambahkan kolom baru pada database dengan nama *location yang mana memiliki nilai awal NULL, setelahnya dari semua data ini tinggal mengisi satu persatu by IP yang ada, kembali ke service [https://ipinfo.io](https://ipinfo.io) service ini memiliki limitasi curl access tapi ada cara lain untuk tetap dapat menggunakan service ini mari kita bedah
-
ipinfo memiliki limitasi akses lewat curl
-
ipinfo memiliki website yang memudahkan pencarian melalui GUI-nya
Dari GUI ini, access yang dilakukan adalah melakukan hit ke endpoint
[https://ipinfo.io/widget/demo/89.187.163.203](https://ipinfo.io/widget/demo/89.187.163.203)endpoint yang berbeda dengan yang dilakukan hit di awal -
ipinfo dengan endpoint
[https://ipinfo.i](https://ipinfo.io)o/$1juga dapat diakses dengan peramban yang mana akan diarahkan ke tampilan berikut ini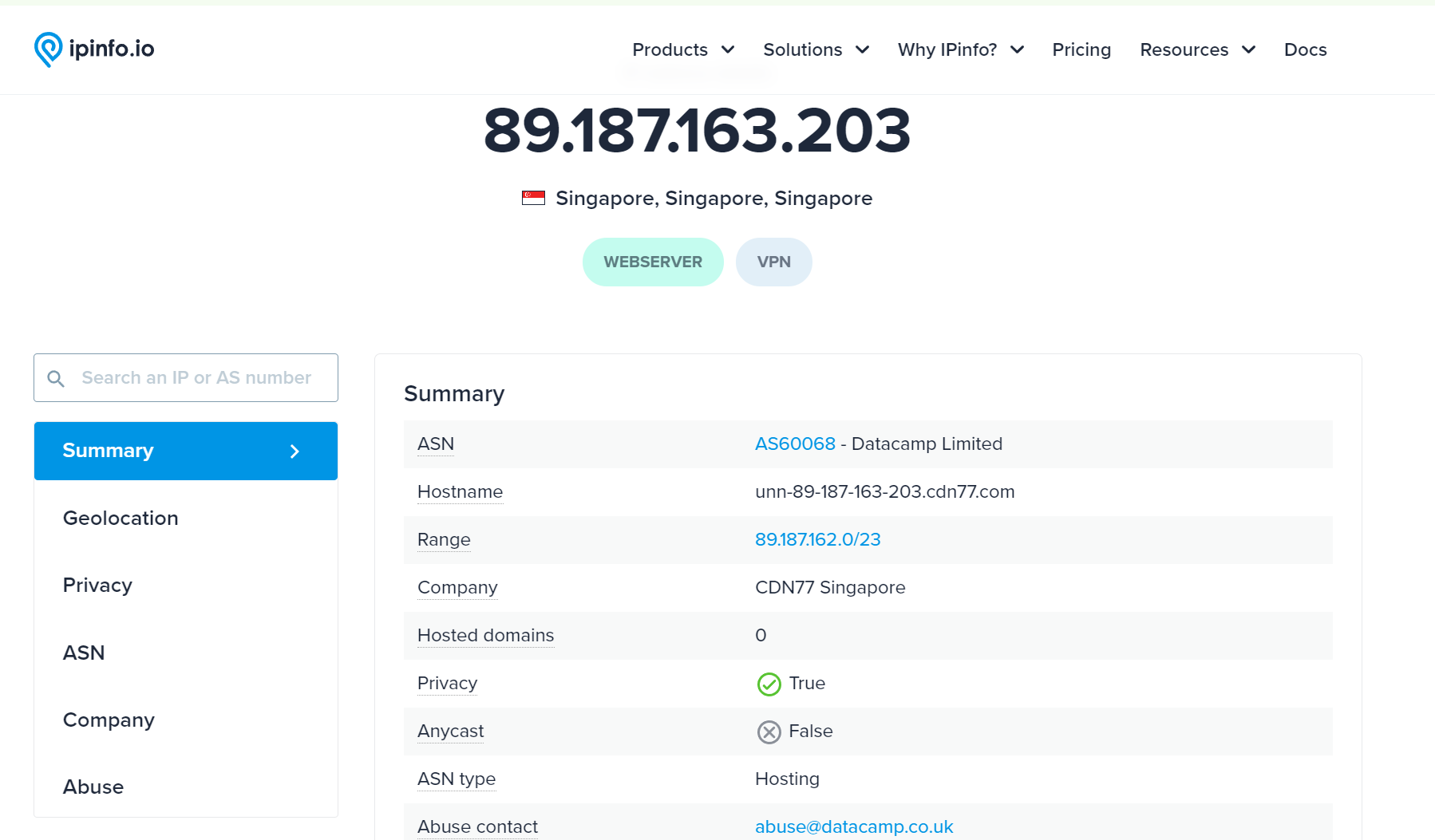
-
Jika akses curl mendapatkan rate limiting maka akses melalui peramban tidak ada masalah, maka hal yang bisa disadari di sini adalah bagaimana pihak ipinfo bisa tau bahwa kita melakukan akses dari peramban? benar, http user-agent dari sini kita dapat melakukan scripting seolah-olah adalah akses browser sembari melakukan scraping, berikut di bawah ini adalah script yang saya gunakan
for x in myresult:
count += 1
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0",
}
regex = r"<tr>\s*<td>Coordinates</td>\s*<td>(.*)</td>\s*</tr>"
response = r.get(base_url.format(x[0]), headers=headers,verify=False).text
coordinates = re.findall(regex, response)
print(count, x[0])
if coordinates:
print(x[0],coordinates[0])
sql = "UPDATE nginx SET location = '{}' WHERE remote_addr = '{}'".format(coordinates[0],x[0])
mycursor.execute(sql)
mydb.commit()
else:
print(x[0],"Not found")Script di atas hanya melakukan regex ke element td untuk mendapatkan Coordinates-nya sembari melakukan update location pada database. Setelahnya dengan bantuan library python bernama folium saya dapat memetakan lokasi dari tiap-tiap visitor pada website saya, berikut ini adalah script sederhana yang saya gunakan (jupyter notebooks)
#from query
iplist = allip['location'].to_list()
m = folium.Map(location=[0, 0], zoom_start=2)
count = 0
for ip in iplist:
count += 1
getloc = ip.split(",")
latitude = getloc[0]
longitude = getloc[1]
folium.Marker([latitude, longitude], popup=ip).add_to(m)
mSetelah menjalankan script di atas maka berikut ini adalah hasil yang dapat dipelajari
-
Worldwide View
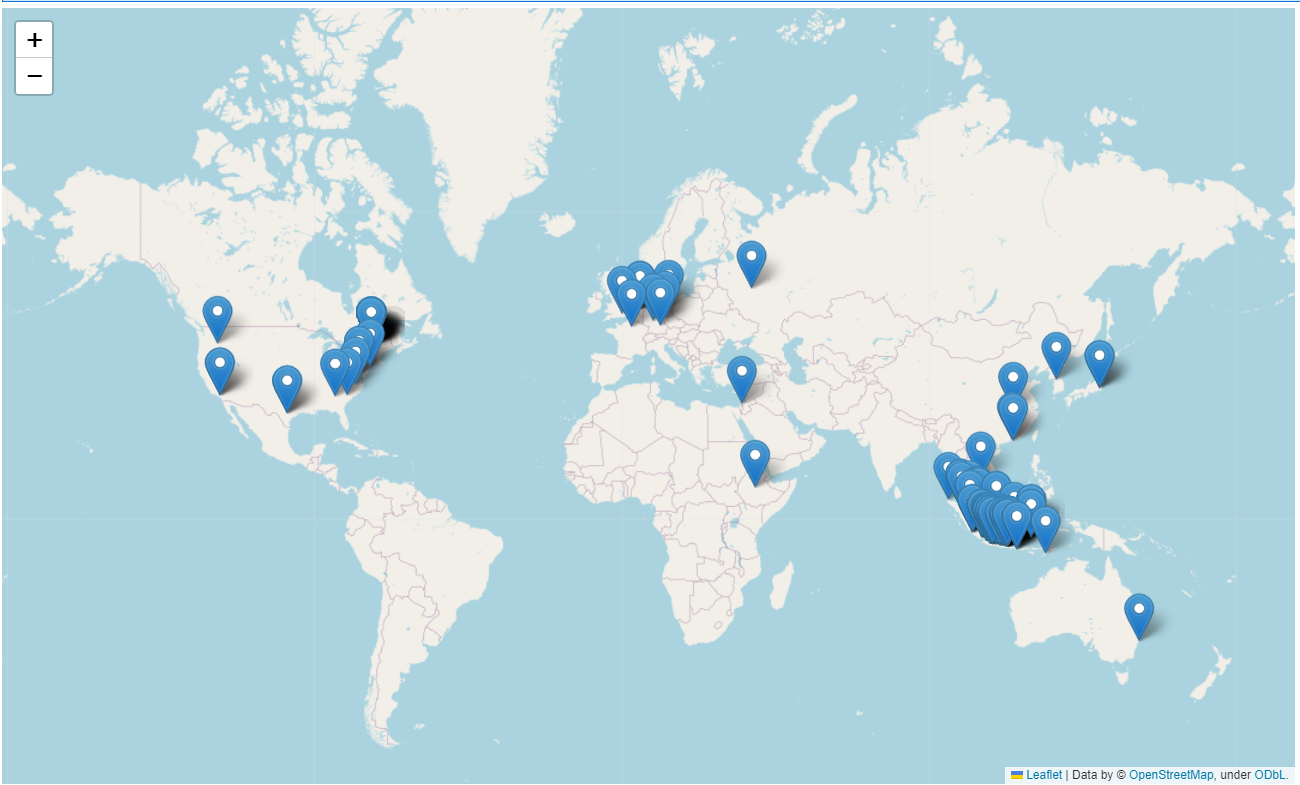
-
Indonesia View
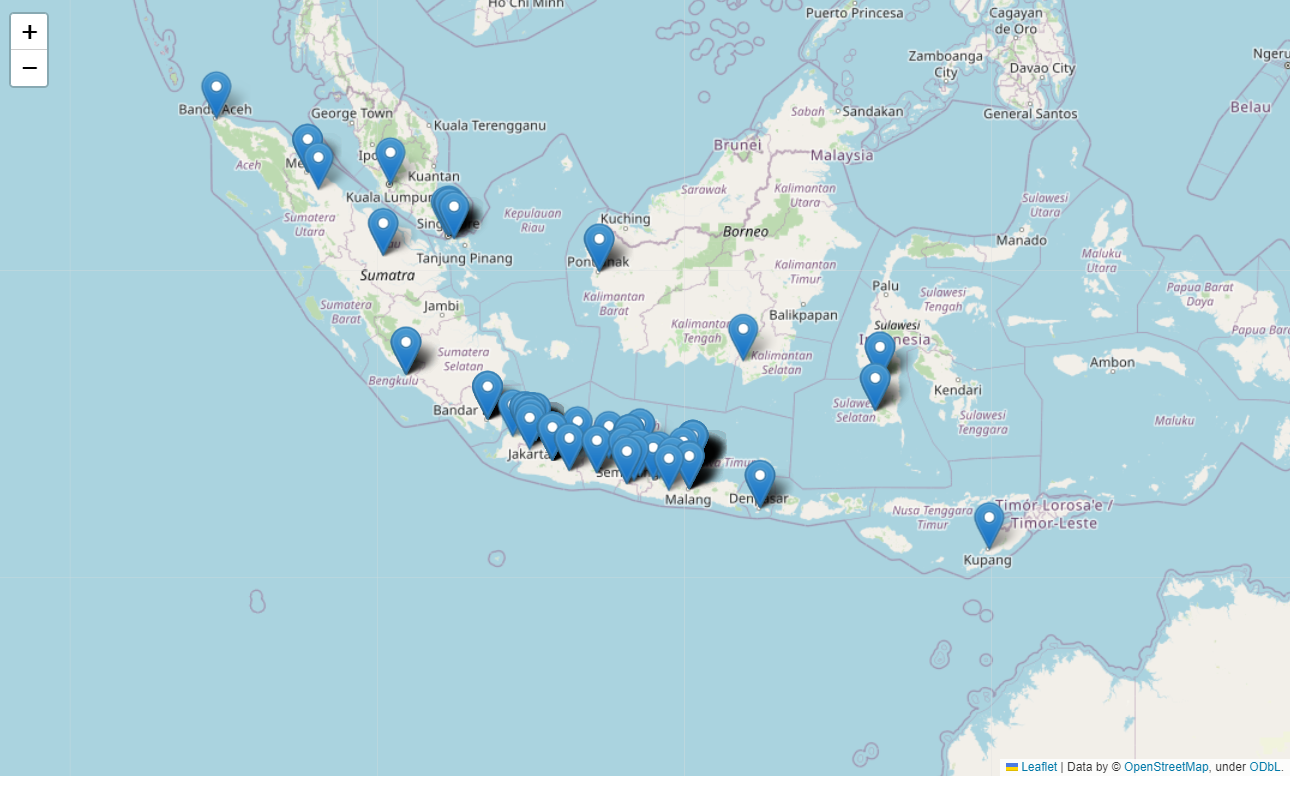
-
Java View
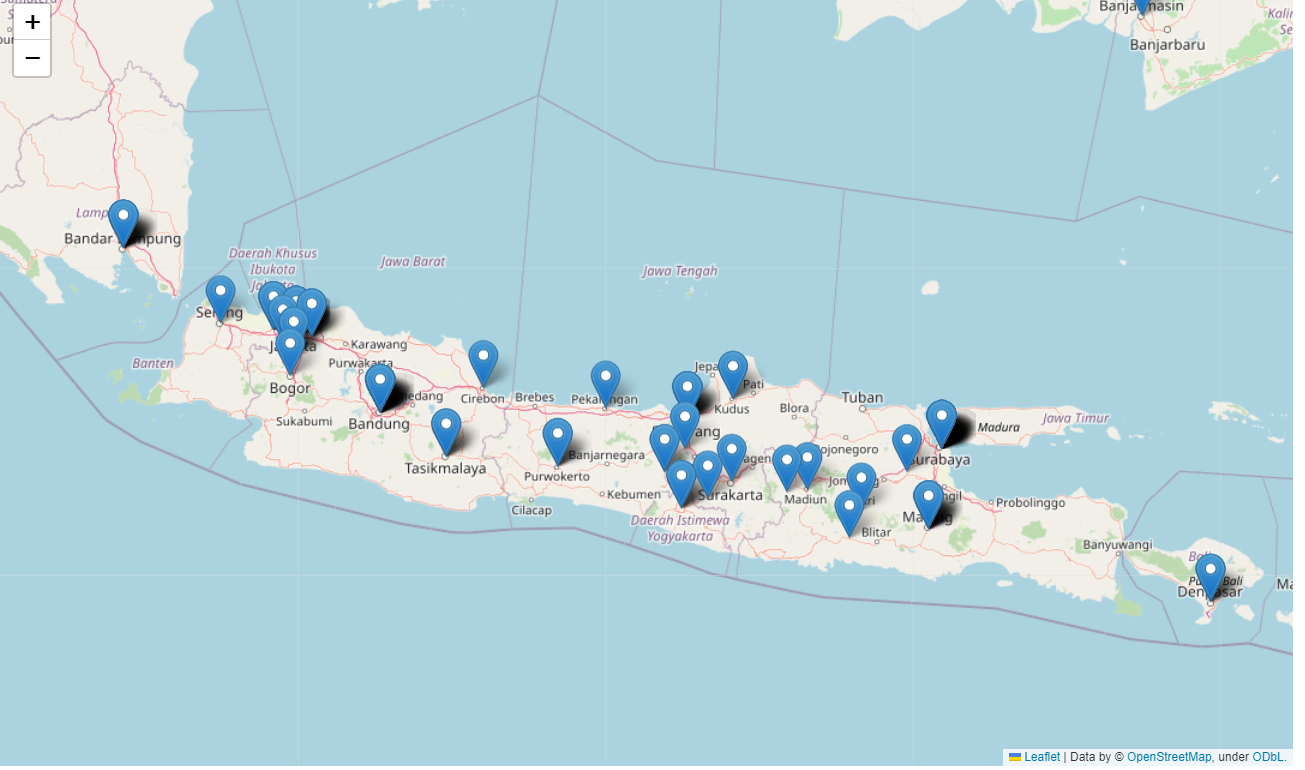
-
Proud East Java View
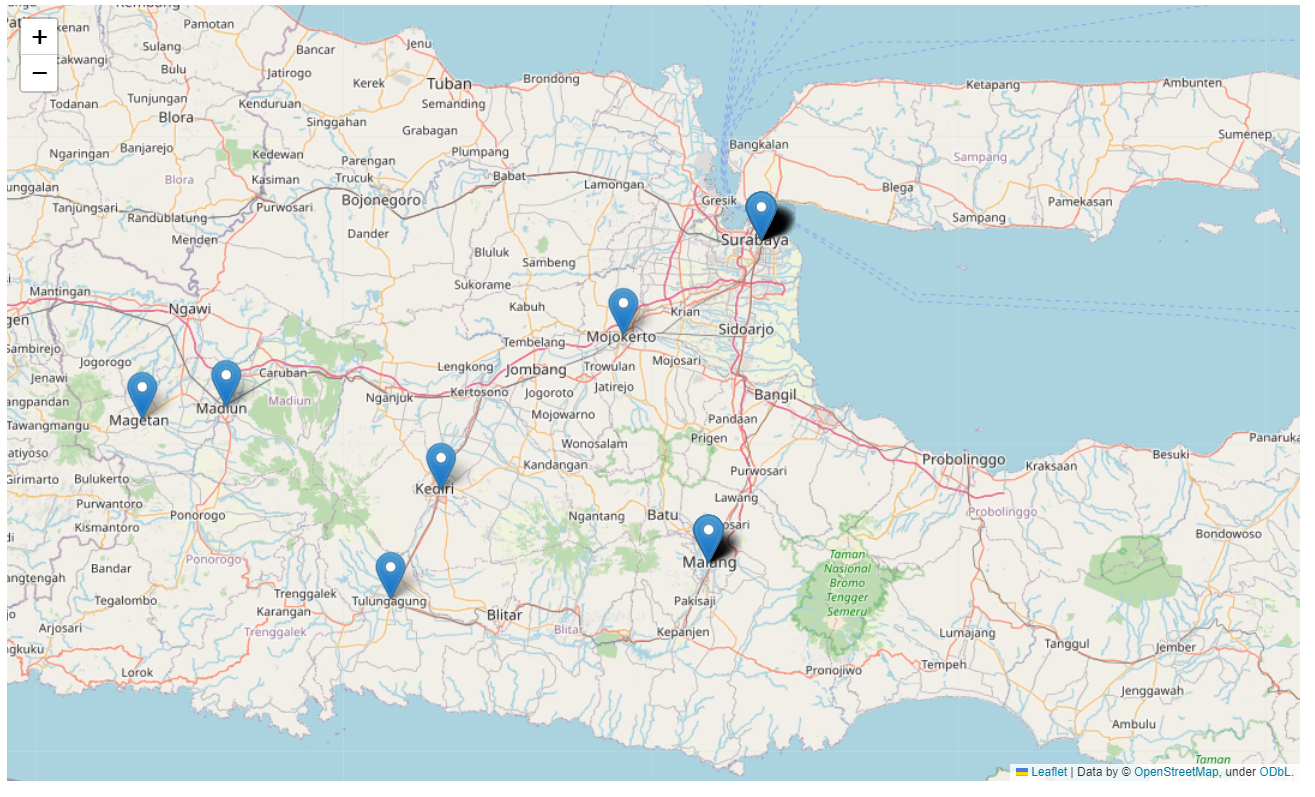
-
Proud Others Java Homies View
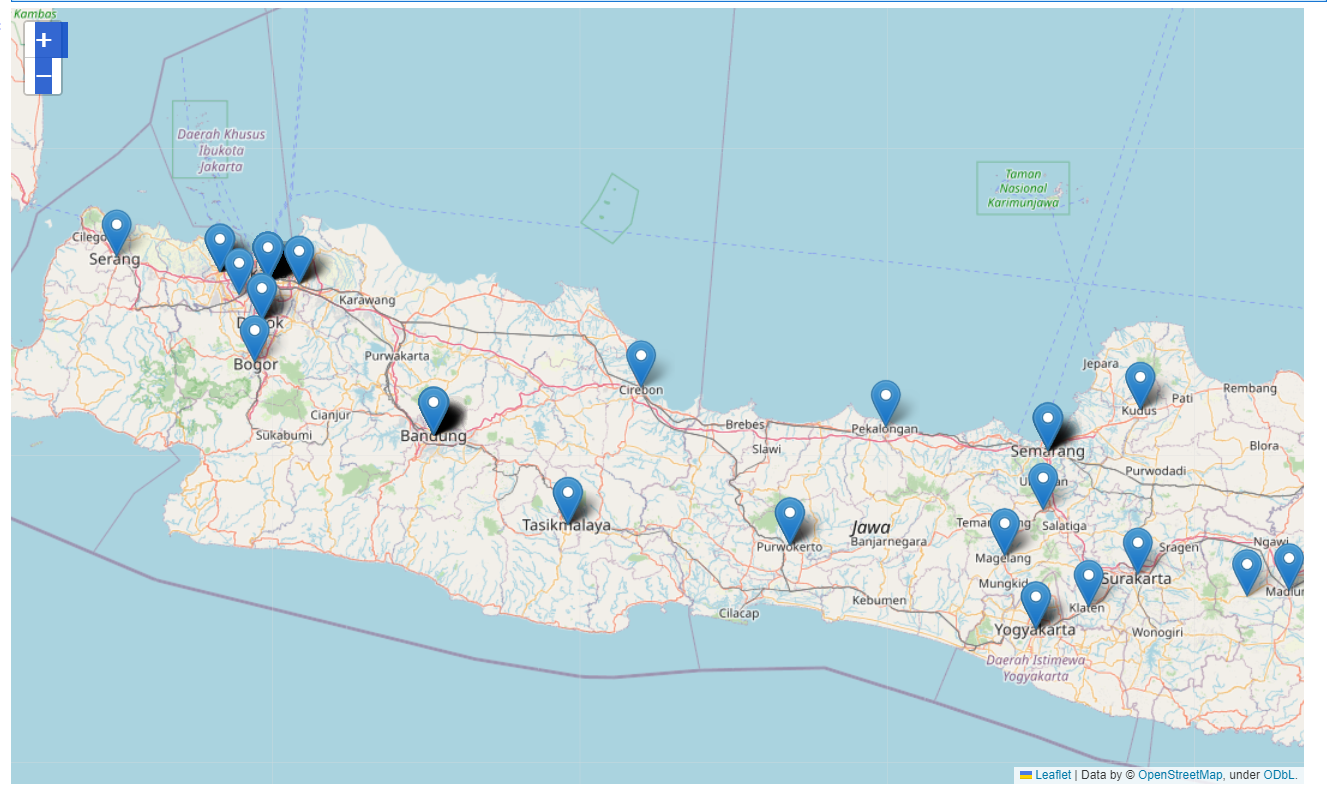
-
Uncle Sam View
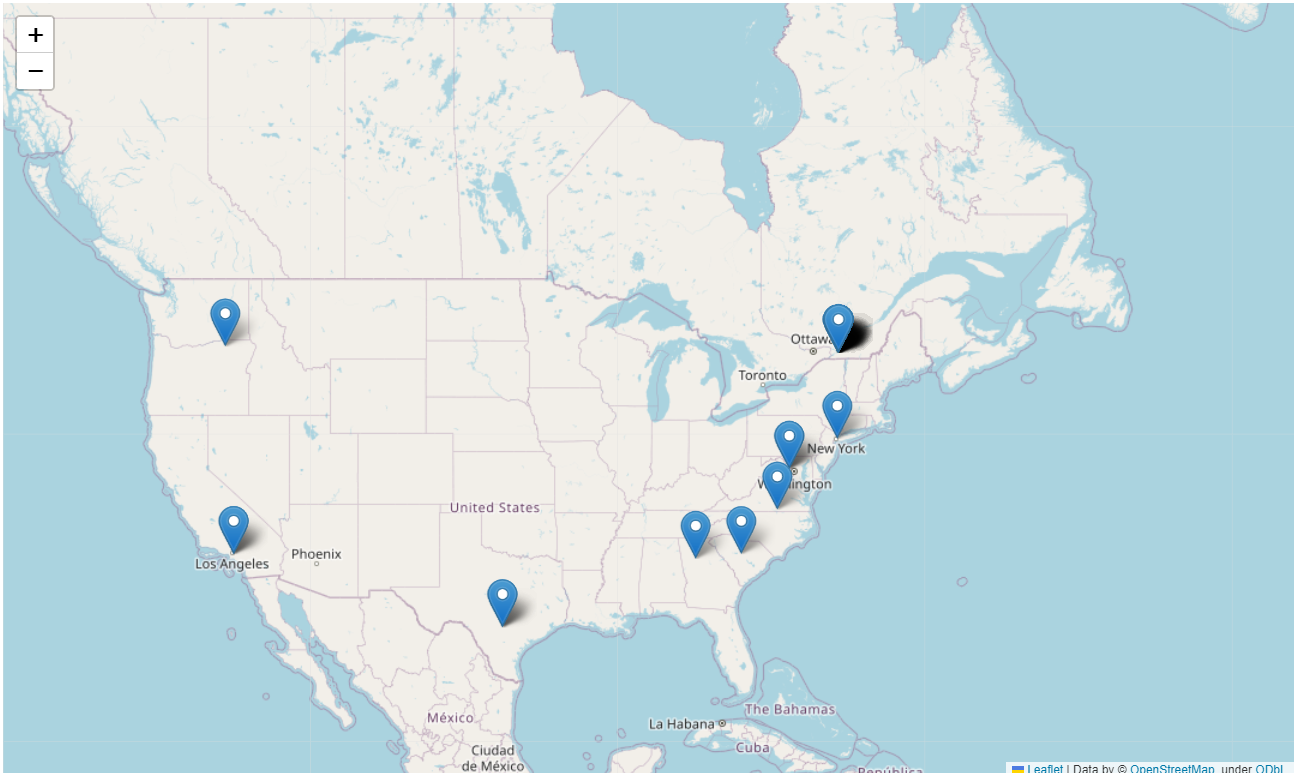
Dari visualisasi di atas sangat menarik bahwa para visitor website saya sangat beragam selain dari negara tercinta Indonesia ini, meskipun perlu diteliti lebih lanjut para visitor luar negeri ini memang seoarng visitor atau sebuah BOT yang kebetulan nyasar di website saya, namun selamat datang! Semoga website saya dapat memberi manfaat yang mendalam bagi siapapun, love!
Explore Visitor URI
Request URI dari para visitor dapat dianalisa lebih lanjut, terutama dengan membandingkan bagaimana bentuk behaviour dari website yang saya sedang kembangkan, website saya hanya memiliki fitur melihat artikel tanpa bisa melakukan komentar atau apapun yang bersifat menyimpan data ke database maka dari itu fokus yang saya cari adalah mencari artikel terbanyak di akses
Stuktur yang dapat dilakukan sorting adalah https://nikkoenggaliano.my.id/read.php?id= maka query sql yang saya gunakan adalah LIKE %read.php?id=% idenya adalah mendapatkan id mana yang terbanyak dikujungi oleh para visitor, sebenarnya bisa langsung menggunakan grouping, namun dalam datanya masih ada yang belum ‘clean’ yang mana membuat proses grouping akan cukup menyusahkan, seperti berikut ini lah contoh yang belum clean
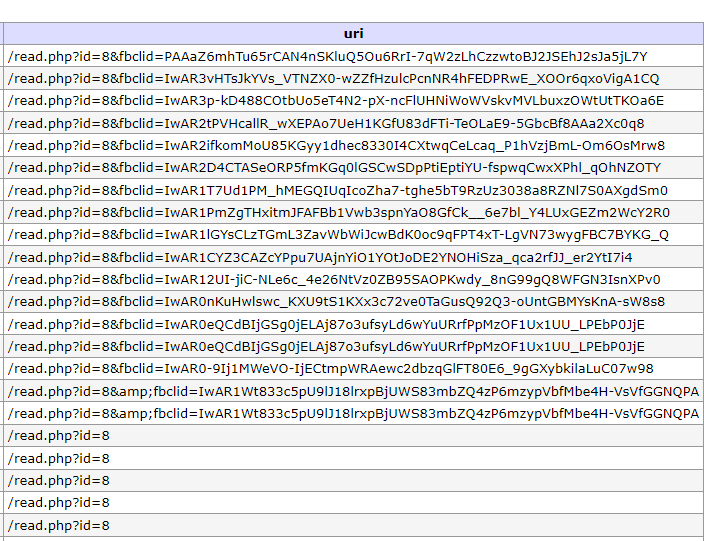
Masih terdapat query parameter tambahan pada database yang kuat dugaan saya berasal dari facebook, dikarenakan ada &fbclid=* cara tercepatnya adalah melakukan filtering by length of columns seperti di bawah inilah full query-nya
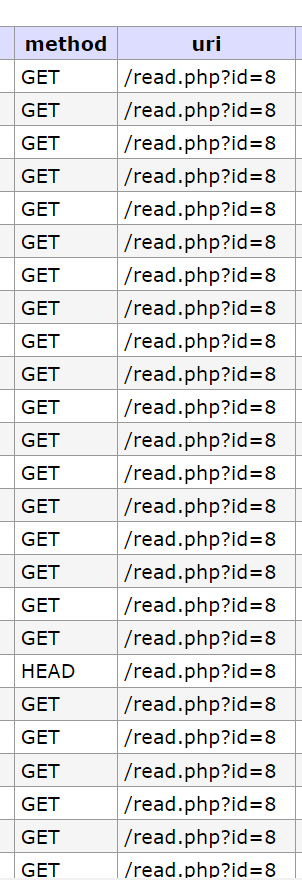
SELECT *
FROM `nginx`
WHERE `status` = '200' AND `uri` LIKE '%read.php?id=%' AND LENGTH(uri) <= 15
ORDER BY `uri` DESCSetelah proses cleaning ini selesai, kita dapat langsung melakukan querying final untuk mendapatkan statistik lengkapnya seperti di bawah ini
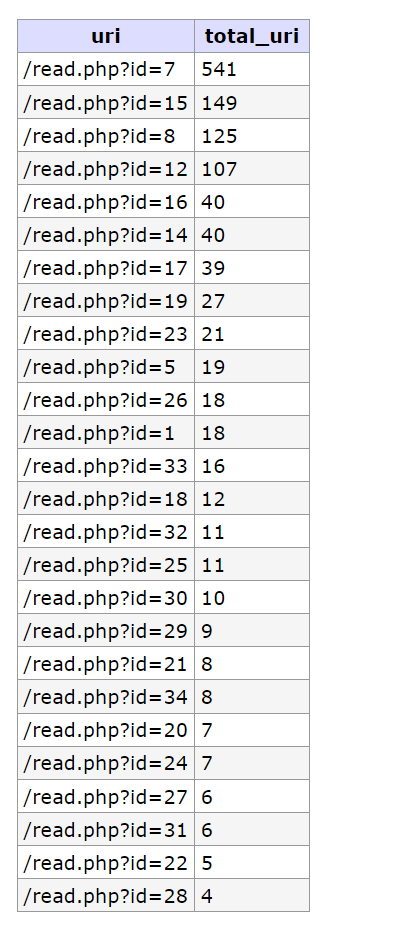
SELECT uri, count(uri) as total_uri
FROM `nginx`
WHERE `status` = '200' AND `uri` LIKE '%read.php?id=%' AND LENGTH(uri) <= 15
GROUP BY `uri`
ORDER BY total_uri DESCDari statistik di atas, ID artikel sudah terlihat mulai dari yang terbanyak sampai yang tersedikit, pada data di atas bisa dielaborasi lebih lanjut yang mana bisa dilihat pada tabel di bawah ini
| ID | Judul Artikel |
|---|---|
| 7 | “LIHAT Foto Paket” scam |
| 15 | Undangan Scam |
| 8 | “Cek Resi J&T.apk” scam |
| 12 | Track them all |
| 16 | Akibat AI |
| 14 | Gacor? |
Dari log access internal terlihat masih artikel seputar “scamming” yang menjadi artikel paling banyak dibaca oleh para visitor, setelahnya diikuti oleh artikel tentang AI dan tentang Malware Gacor yang menyerang beberapa website. Semoga ke depan saya tetap dapat menyajikan artikel yang menyenangkan untuk dibaca!
User-Agent Things
User-Agent adalah sebuah identitas yang lazimnya berada pada HttpClient yang umumnya memang berfungsi untuk memberikan identifikasi terkait HttpClient tersebut, jika menggunakan peramban Mozzila yang pasti User-Agent-nya akan memiliki string-string Mozzila begitupun yang lainnya, namun User-Agent ini dapat dilakukan customize yang mana pengguna sebenarnya dapat menset apapun suka-suka saja, dengan banyak tujuan apapun, seperti pada sesi scraping di atas saya melakukan bypass rate limiting dengan memanfaatkan User-Agent yang sama dengan yang ada pada sebuah peramban.
Berikut inilah saya lampirkan tangkapan layar berupa statistik para pengguna berdasarkan User-Agent dari yang terbanyak ke yang paling sedikit

Dari statistik di atas, terlihat banyak sekali User-Agent yang memiliki awalan Mozzila tapi apakah mereka benar-benar Mozzila? mengutip penjelasan dari sini
You now see “Mozilla” at the start of different browser user agents because, back in the day, Mozilla was the only browser that supported frames. When web servers checked the text string and it contained the word “Mozilla”, it knew to send web pages containing frames—the rest were sent old pages.
Dari penjelasan di atas terlihat bahwa Mozzila ada dikarenakan pada jaman dahulu untuk memberi signal bawa browser tersebut supported frames. Dikarenakan terlalu banyak string dari User-Agent maka cara untuk gampang melakukan visualisasi adalah dengan menggunakan wordcloud, dengan mengumpulkan banyak string dan wordcloud akan membuatkan summary dari semua kata yang sering muncul, namun ada beberapa tahapan yang wajib dikerjakan sebelum dapat menggunakan wordclouds dengan optimal di antaranya adalah
- Data Cleaning
- Data Normalize
Dari semua proses optimasi di atas saya mengembangkan sebuah simple function python untuk melakukan hal tersebut, berikut di bawah ini lah script yang saya kembangkan
parse_agent = pd.read_sql('SELECT user_agent, count(user_agent) as total FROM `nginx` GROUP BY user_agent ORDER BY total DESC', con=engine)
text = ""
def clean_data(data):
cleaned_data = re.sub(r'[^a-zA-Z\s]', '', data)
cleaned_words = [word for word in cleaned_data.split() if len(word) > 1]
return " ".join(cleaned_words)
for x in parse_agent['user_agent']:
cleaning = clean_data(x)
text += " " + cleaning+ " "Hasil dari variable text akan dilanjutkan oleh fungsi wordcloud untuk dijadikan sebuah gambar yang memiliki summary seperti pada gambar di bawah ini

Dari gambar di atas sepertinya tidak menjelaskan apapun dengan baik, namun yang pasti dari gambar di atas kita dapat mengenali kata apa saja yang paling sering muncul dari semua User-Agent yang ada pada database.
Referer Tell Me Alot
Salah satu informasi yang dapat digali adalah referer http singkatnya referer kolom pada database yang saya telah simpan adalah untuk dapat mengetahui “sebenarnya dari mana sih” visitor website saya ini, jika dikelompokan sesuai dengan jumlahnya seperti inilah tampilan tangkapan layarnya
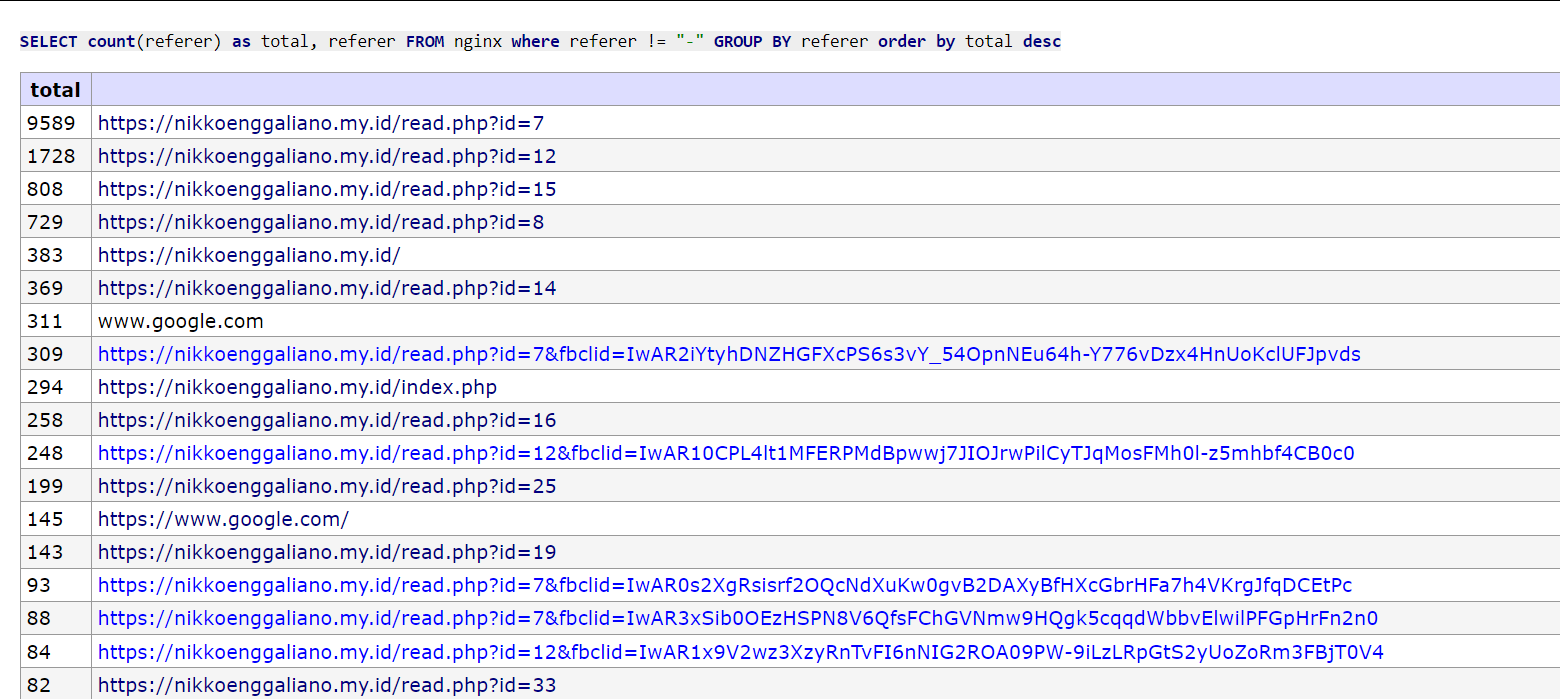
Urutan teratas sumber visitor saya masih berasal dari website saya sendiri, jika dari website saya sendiri maka “tidak asik”, maka saya akan menghilangkan referer selain dari website yang saya kembangkan dan berikut inilah hasilnya
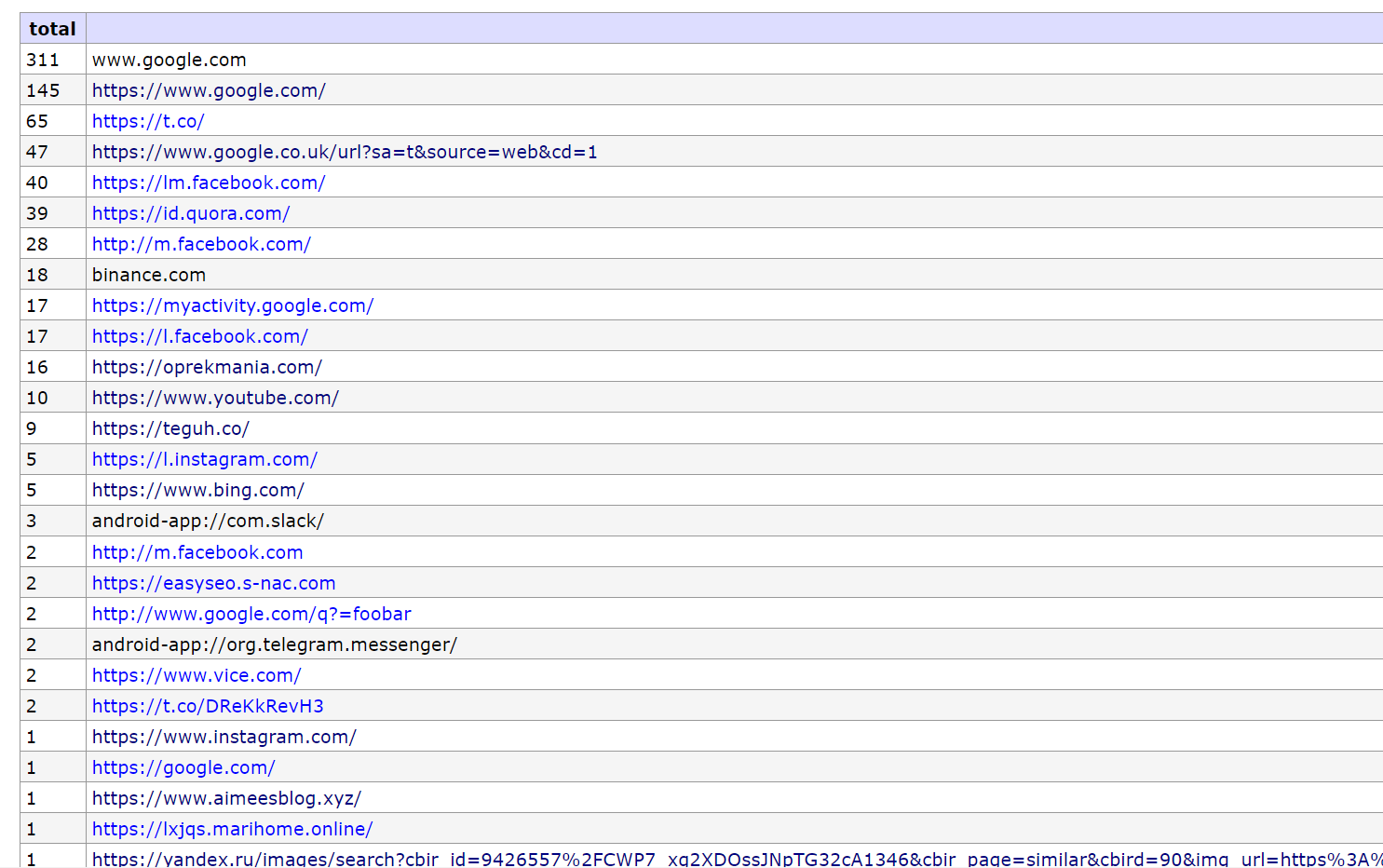
Banyak sumber visitor saya tetap dari google sisanya ada facebook dan beberapa website besar lainnya seperti quora dan vice, menarik tapi dari artikel mana visitor mengunjungi website saya? cara terbaiknya bagi saya adalah menggunakan google dorking / simple keywords untuk memastikan dari artikel mana visitor ini berasal
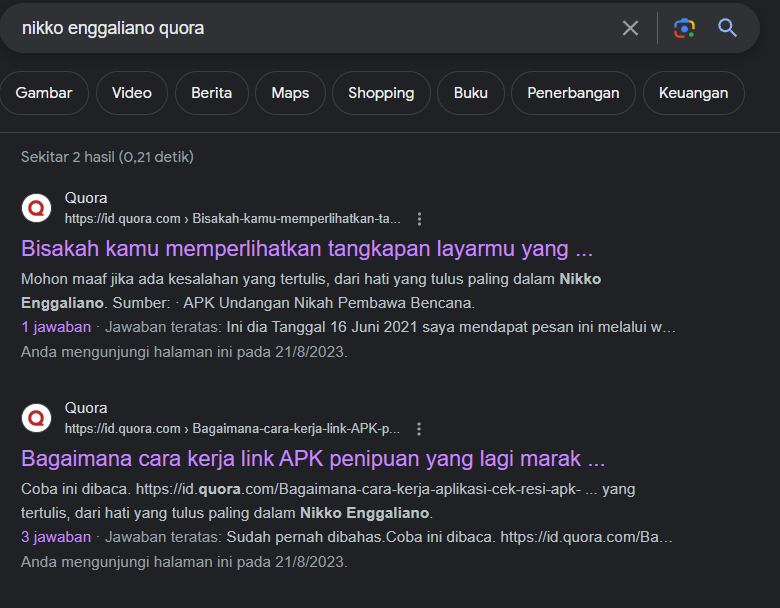
Dari artikel di ataslah para visitor website saya datang, terima kasih telah banyak yang mengutip website saya, saya sangat senang jika saya dapat menyebar manfaat, semoga seterusnya saya juga dapat membuat tulisan yang bermanfaat! Mohon doanya!
Outside Collection, Google Analytic
Selain dapat mengali informasi secara manual melalui Nginx Access Log, saya juga memasang Google Analytic sebagai analysator platform tambahan yang mana lebih praktis dan lebih efesien penggunaannya, apa saja yang dapat disajikan oleh Google Analytic? di bawah ini mari kita lihat satu persatu dan yang disajikan adalah data mulai dari Januari 2023 sampai dengan Agustus 2023.
-
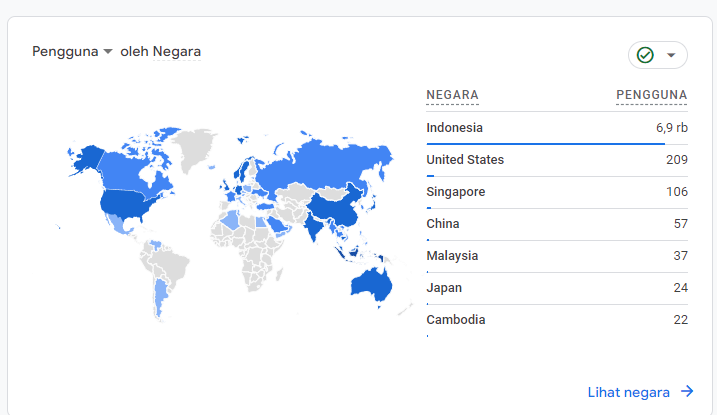
Visitor by Country
-
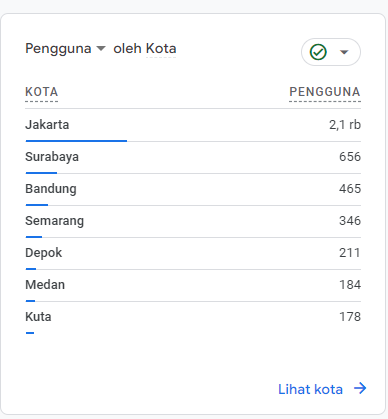
Visitor by Indonesia City
-
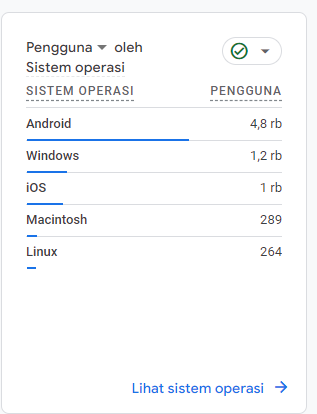
Visitor by OS
-
Visitor by Devices
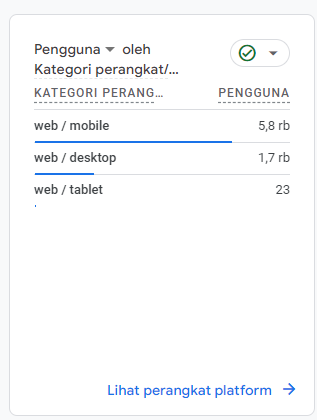
-
Visitor by Browser
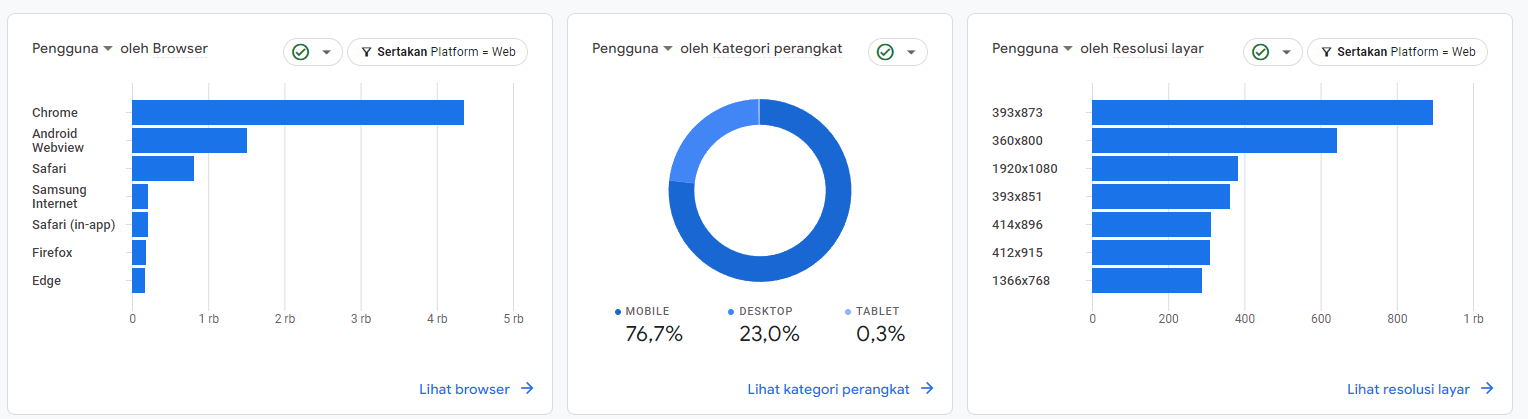
-
All Visitor this Year (August)
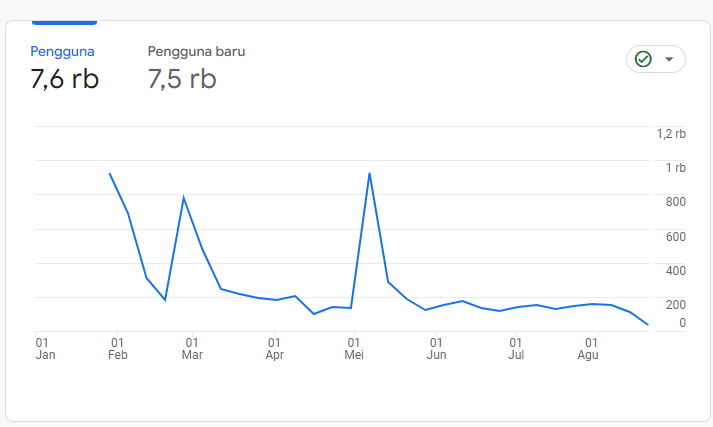
-
Visitor by Pages
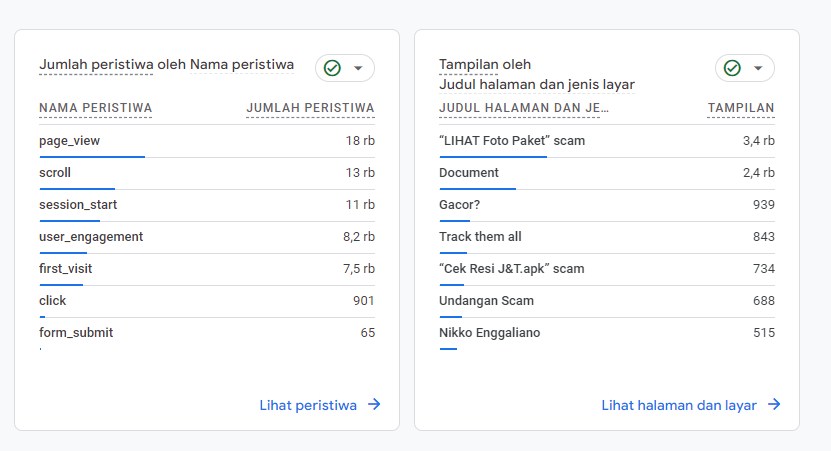
Dari data yang dapat disajikan oleh Google Analytic ini beberapa data mirip dengan hasil analisa manual, lalu artikel yang paling banyak dikunjungi juga adalah artikel yang berkaitan dengan analisa Scamming, analisa yang dilakukan Google Analytic terlihat lebih mudah dipahami dan lebih mudah diimplementasikan juga, namun analisa manual dari Access Log juga punya “kesenangannya sendiri” haha, naif memang dasar aku.
Penutup
Senang rasanya dapat menyelesaikan artikel kali ini di tengah hiruk pikuk padatnya aktifitas sehari-hari, menulis dan melakukan simple scripting bagi saya tetap terasaya menyenangkan di sisi lain juga tetap mengasa skill coding agar tidak “mati” dikarenakan sehari-hari sudah tidak seaktif dulu untuk coding.
Teman-teman, terima kasih ya telah membaca artikel yang telah saya tulis kali ini, semoga ada sesuatu yang bermanfaat dari artikel yang saya tulis penuh dengan cinta ini, jya. Mohon maaf jika terdapat kesalahan teori atau kesalahan kata yang tertulis pada artikel saya kali ini, saya akan sangat senang jika dapat ditegur teman-teman jika ada kesalahan yang saya buat.
Contact me t.me/rainysm